


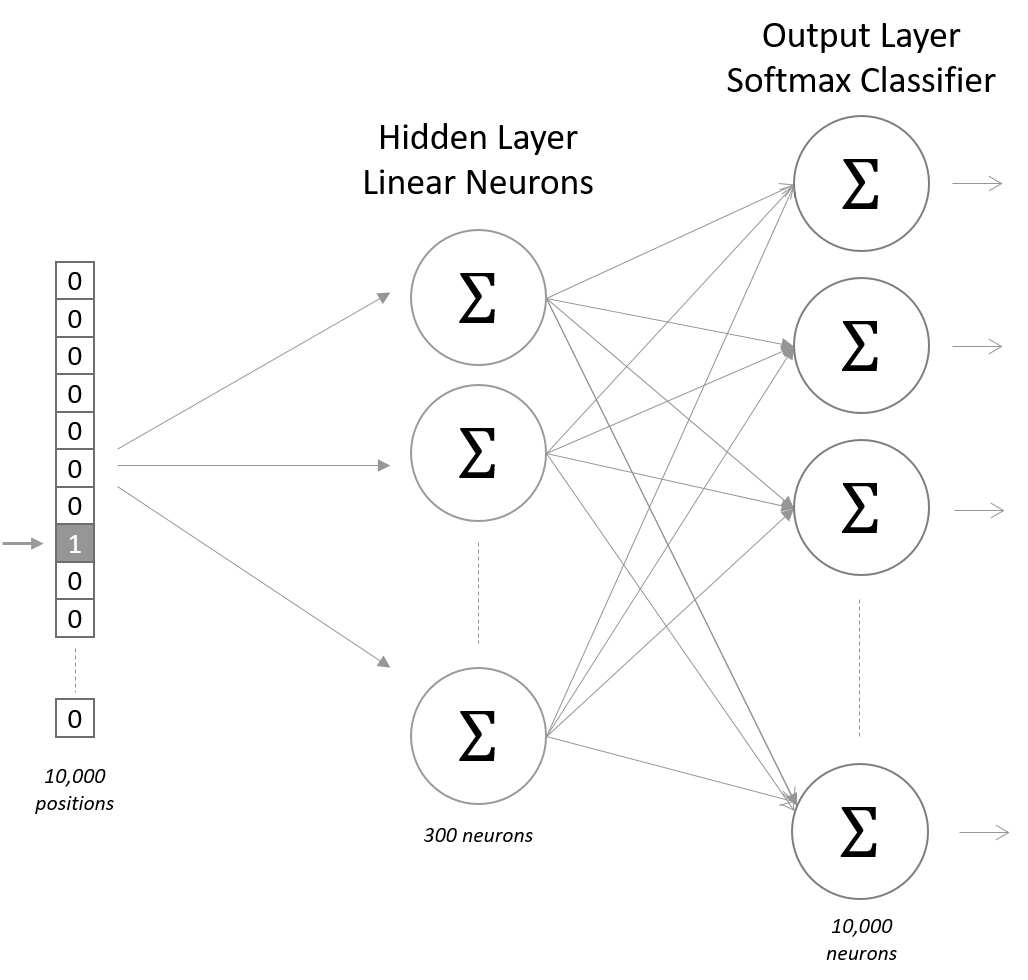

مدل زبانی سیلک (Sialk)
مدل زبانی سیلک (Sialk) بصورت پایه (from scratch) در شرکت MCINEXT به منظور تولید یک مدل فارسی 1.3 میلیاردی توسعه داده شده است. برای آموزش این مدل از پیکره دادگان فارسی استفاده شده است. این مدل به دلیل حجم کوچک 1.3 میلیاردی آن از سرعت بالایی برخوردار است.

مدل زبانی بزرگ آهوران (Ahoran)
مدل زبانی بزرگ آهوران (Ahoran) بصورت Continual pretraining در شرکت MCINEXT به منظور تولید یک مدل بومی بزرگ فارسی ( 8 میلیارد پارامتر) توسعه داده شده است. آهوران بر روی مجموعه دادگان متنی فارسی بصورت continual pretraining آموزش دیده شده و همواره با دادگان جدید بهروزرسانی می شود.

مدل زبانی بزرگ آوا (Ava)
مدل آوا (Ava) در گروه MCINEXT همراه اول یک مدل زبانی فارسی با 13 میلیارد پارامتر است که بر مبنای محصول aya شرکت cohere و به کمک روش fine tuning در گروه MCINext توسعه داده شده است و قابلیت پاسخگویی به سوالات در زمینه اطلاعات عمومی و به ویژه RAG می باشد.