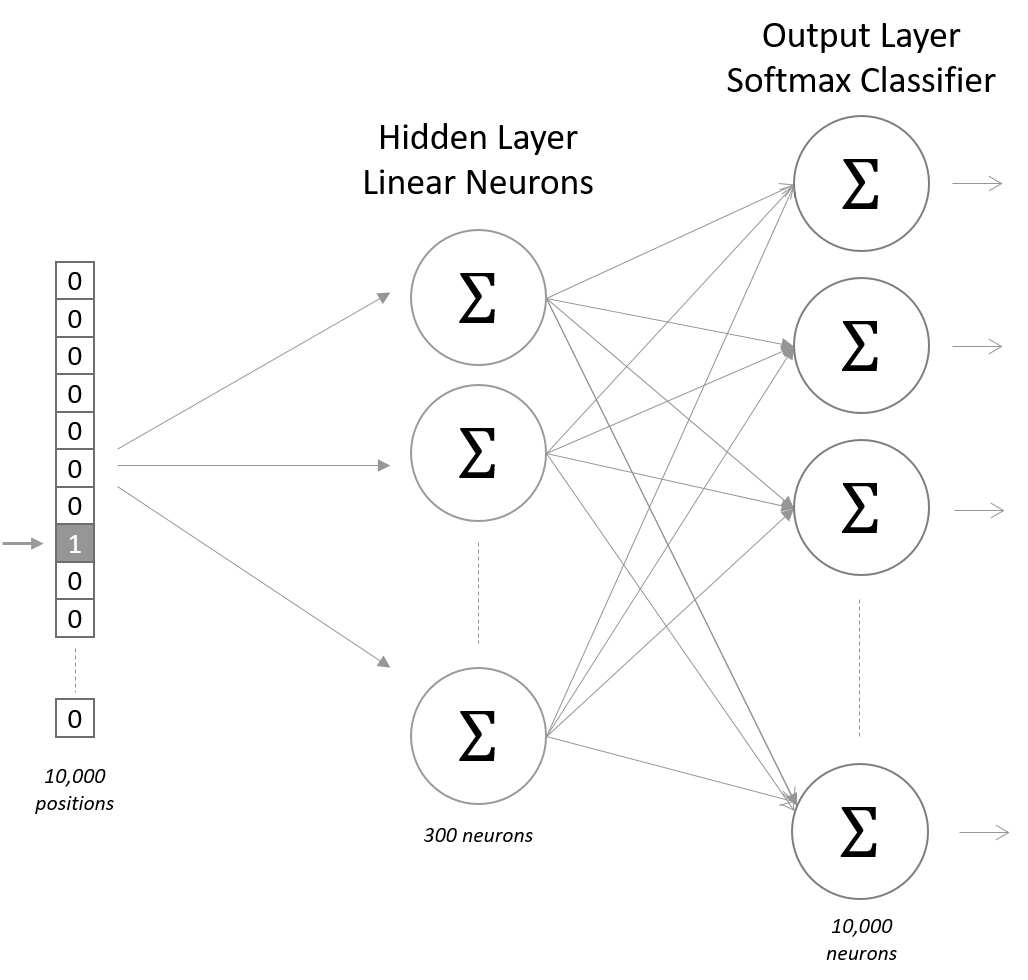
In the digital age, the need for language models capable of processing multiple languages simultaneously is more pressing than ever. Our team is developing a trilingual language model in Persian, Arabic, and English to meet this demand. Leveraging advanced deep learning techniques and natural language processing, this model promises significant achievements in both accuracy and speed.
Key Features of the Model
Smaller Model Size
One of the primary advantages of this model over existing multilingual models is its smaller size. This feature reduces the need for extensive hardware resources, allowing the model to perform well even on devices with limited processing power.
Faster Inference Speed
The compact size of the model not only makes it more resource-efficient but also enables faster inference, providing quick and accurate results.
Coverage of Three Major Languages
By supporting Persian, Arabic, and English, this model addresses the linguistic needs of a vast user base, enhancing its utility across different regions.
Training on a Large Volume of Data
The model has been trained on a substantial dataset, which contributes to its high accuracy and reliability in various natural language processing tasks.
Given that fine-tuning significantly enhances the accuracy and performance of language models in specific natural language processing applications, we have committed to fine-tuning this model for various tasks such as machine translation, sentiment analysis, and question answering. Therefore, in addition to the proposed general model, task-specific models will also be provided.
This language model has been developed by the experts at NEXT MCI, aiming to provide intelligent interactive tools for multilingual users. In alignment with our commitment to contributing to the AI ecosystem in the country, we plan to release this model as open-source in the near future.