


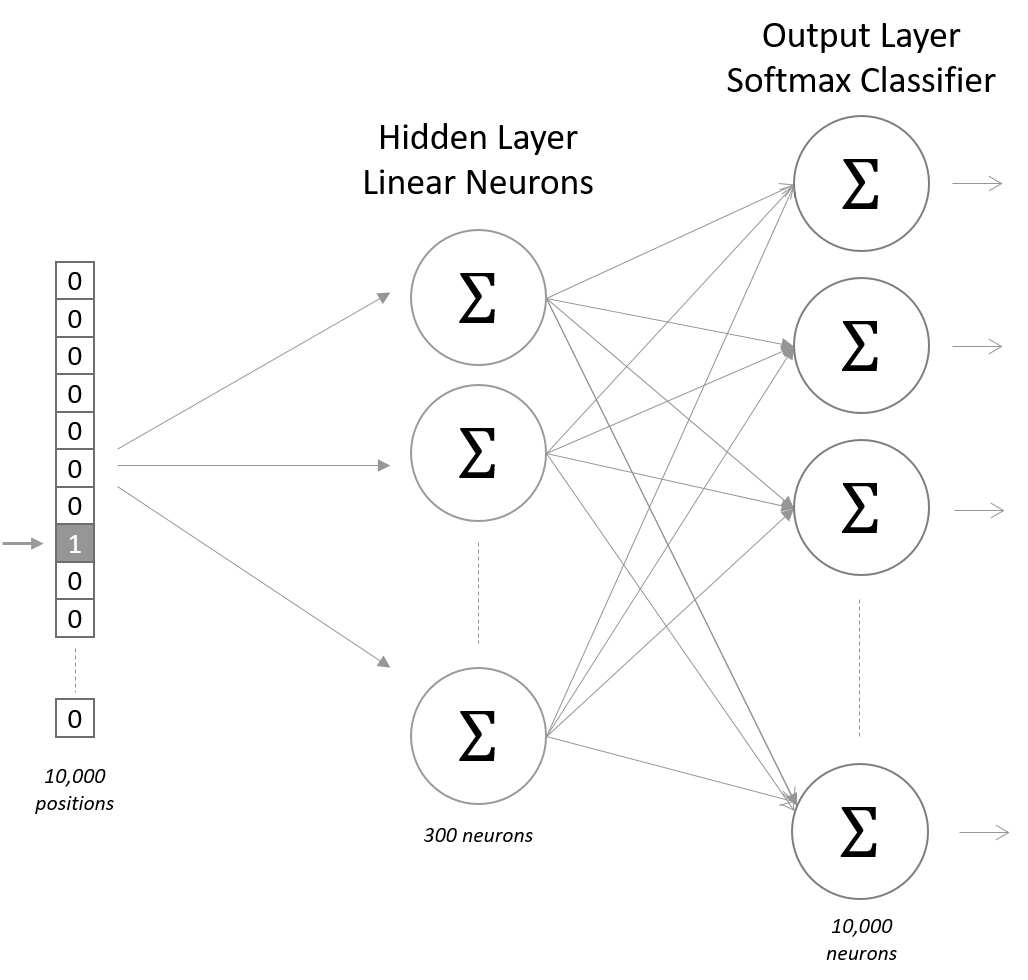

Sialk Language Model
The Sialk language model (Sialk) was developed from scratch by MCINEXT to produce a 1.3-billion-parameter Persian model. This model was trained using Persian language datasets and, due to its small size (1.3 billion parameters), is highly efficient in terms of speed.

Ahoran Large Language Model
The Ahoran large language model (Ahoran) was developed by MCINEXT through continual pretraining to create a native large Persian model (8 billion parameters). Ahoran has been continually trained on Persian text corpora and is regularly updated with new datasets.

Ava Large Language Model
Ava, developed by MCINEXT in collaboration with MCI, is a Persian language model with 13 billion parameters. Built on Cohere’s Aya product and fine-tuned by the MCINEXT team, Ava is capable of answering questions related to general knowledge and especially excels in RAG (Retrieval-Augmented Generation).